[ECW Quals 2020] MD5 collision - The Prestige
Introduction
This challenge was part of the European Cyber Week qualifications.
The goal of this challenge was to find a valid MD5 collision of a given image to retrieve the flag.
Explanation
MD5 collisions
It’s easy to compute two different messages that will have the same MD5 hash. However, it’s currently impossible in a reasonable time to find a message that will have a specific hash. Since this challenge has to be solved in two weeks, there is something else.
Image analysis
Since this challenge is in the steganography category, let’s check the images properties.
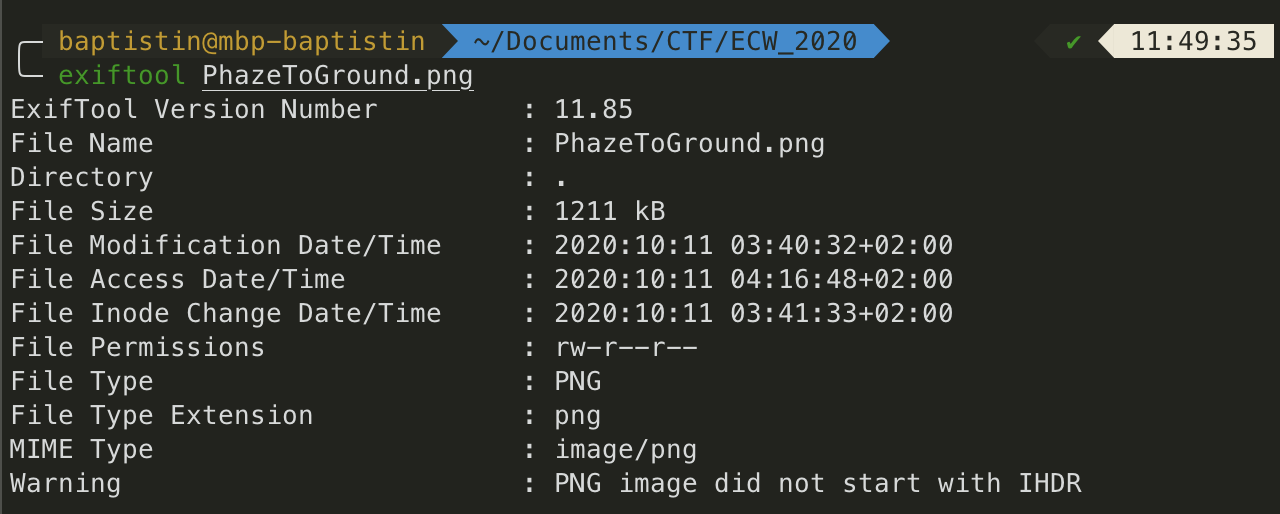
The warning tells us that there may be another header as IHDR should be the first one in theory.
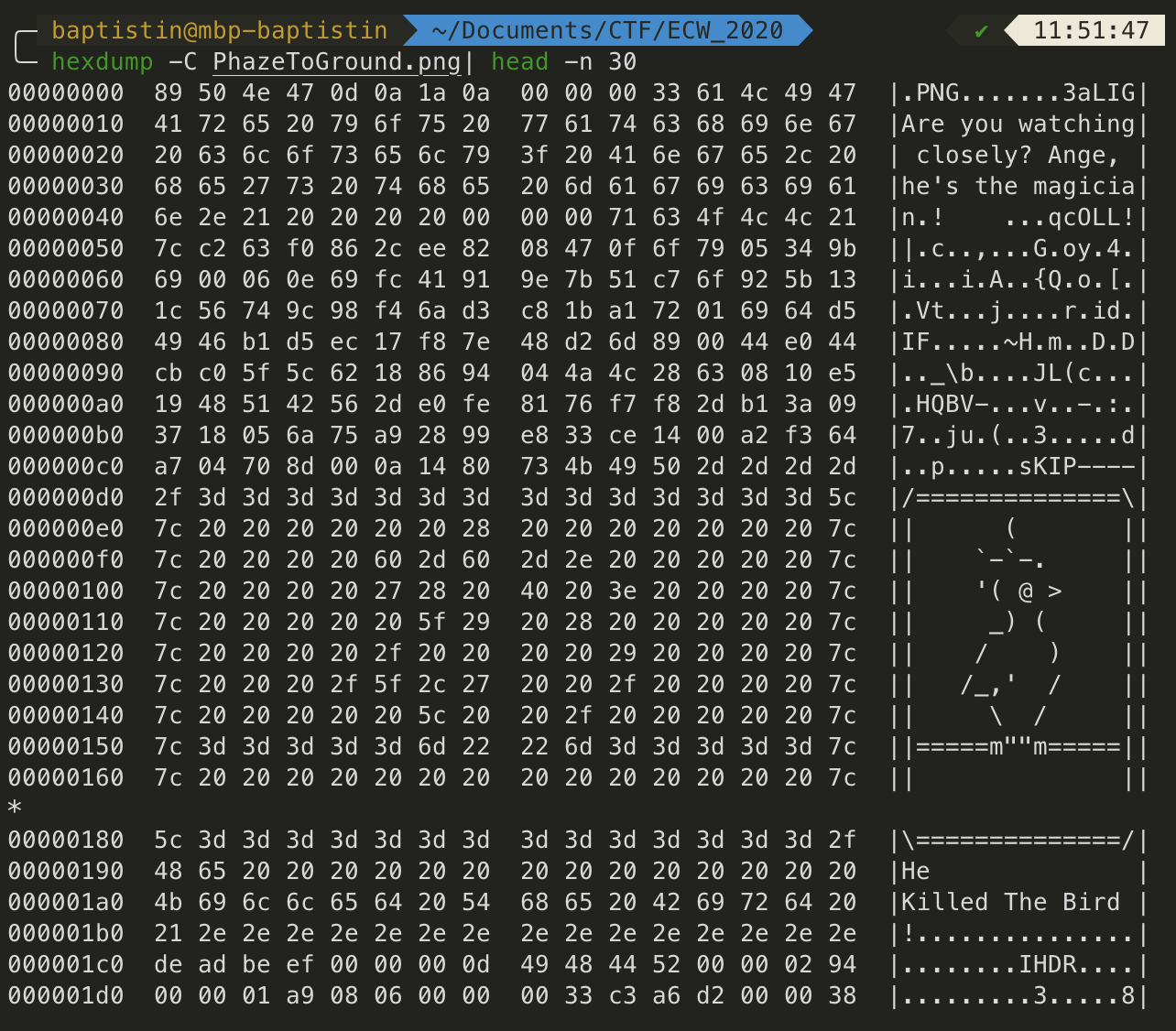
We’ve a lot of information here. Let’s to some research.
RTFM
After a quick research, I found a presentation made by Ange Albertini and an interesting github repository by Ange Albertini and Marc Stevens.
So there are 2 attacks:
- Identical prefix: choose a prefix and compute some data that will be appended to each prefix to have a collision. Then it’s possible to add the same suffix and both files will have the same MD5 hash.
- UniColl attack
- FastColl attack
- Chosen prefix: it’s the same concept as previously explained except we can choose 2 different prefix.
I really encourage you to check out the github repository to have further information on how the attacks works.
The repository also contains a lot of scripts to make valid files collisions. Let’s check out png.py:
#!/usr/bin/env python
# a script to collide 2 PNGs via MD5
# with optimal structure and either:
# - correct CRCs with appended data
# - with synched comments and incorrect CRCs
import sys
import struct
# Use case: ./png.py yes.png no.png
fn1, fn2 = sys.argv[1:3]
with open(fn1, "rb") as f:
d1 = f.read()
with open(fn2, "rb") as f:
d2 = f.read()
PNGSIG = "\x89PNG\r\n\x1a\n"
assert d1.startswith(PNGSIG)
assert d2.startswith(PNGSIG)
# short coll
with open("png1.bin", "rb") as f:
blockS = f.read()
# long coll
with open("png2.bin", "rb") as f:
blockL = f.read()
ascii_art = """
vvvv
/==============\\
|* *|
| PNG IMAGE |
| with |
| identical |
| -prefix |
| MD5 collision|
| |
| by |
| Marc Stevens |
| and |
|Ange Albertini|
| in 2018-2019 |
|* *|
\\==============/
""".replace("\n", "").replace("\r","")
assert len(ascii_art) == 0x100 - 3*4 # 1 chunk declaration + crc
# 2 CRCs, 0x100 of UniColl difference, and d2 chunks
skipLen = 0x100 - 4*2 + len(d2[8:])
###############################################################################
#
# simplest (w/ appended data and incorrect CRCs)
"""
Ca{ Ca{ Ca{
} } }
Cc{ Cc{ Cc{
-------- -------- --------- <== collision blocks
}a }a ..
C1{ C1{ ...
}b .. }b
D1 .. D1
} } .
D2 D2 ..
"""
from binascii import crc32
_crc32 = lambda d:(crc32(d) % 0x100000000)
suffix = struct.pack(">I", _crc32(blockS[0x4b:0xc0]))
suffix += "".join([
# sKIP chunk
struct.pack(">I", skipLen),
"sKIP",
# it will cover all data chunks of d2,
# and the 0x100 buffer
ascii_art,
"\xDE\xAD\xBE\xEF", # fake CRC for cOLL chunk
d2[8:],
# long cOLL CRC
"\x5E\xAF\x00\x0D", # fake CRC for sKIP chunk
# first image chunk
d1[8:],
])
with open("collision1.png", "wb") as f:
f.write("".join([
blockS,
suffix
]))
with open("collision2.png", "wb") as f:
f.write("".join([
blockL,
suffix
]))
###############################################################################
#
# Appended data strategy, with correct CRCs
# (make sure the aLIG chunk has valid CRCs in your prefix)
# short cOLL CRC
suffix = struct.pack(">I", _crc32(blockS[0x4b:0xC0]))
suffix += "".join([
struct.pack(">I", skipLen),
"sKIP",
# it will cover all data chunks of d2,
# and the 0x100 buffer
ascii_art
])
# long cOLL CRC
suffix += struct.pack(">I", _crc32((blockL+suffix)[0x4b:0x1C0]))
suffix += d2[8:]
# CRC for jUMP after d2's IEND
suffix += struct.pack(">I", _crc32((blockS+suffix)[0xc8:0xc8 + 4 + skipLen]))
# first image chunks
suffix += d1[8:]
with open("collision-crc1.png", "wb") as f:
f.write("".join([
blockS,
suffix
]))
with open("collision-crc2.png", "wb") as f:
f.write("".join([
blockL,
suffix
]))
###############################################################################
#
# synched-chunks strategy (no appended data, but incorrect CRCs)
"""
Ca{ Ca{ Ca{
} } }
Cc{ Cc{ Cc{
--------- --------- --------- <== collision blocks
}a .. }a
C1{ ... C1{
}b }b ..
D1 D1 ..
C2{ C2{ ...
} . }
D2 .. D2
C3{ ... C3{
} } } . } }
IEND IEND IEND
"""
suffix2 = "".join([
"CRco",
# EndA of collision
struct.pack(">I", 0x100 + len(d1[8:-3*4])),
"sKIa",
# it will cover all data chunks of d2,
# and the 0x100 buffer
ascii_art,
"^^^^",
# EndB of collision
d1[8:-3*4],
struct.pack(">I", 4*3 + len(d2[8:-3*4])),
"sKIb",
"crAA",
d2[8:-3*4],
struct.pack(">I", 0),
"sKIc",
"crBC", # for both sKIb and sKIc - hard to be correct for both
d1[-3*4:],
])
with open("collision-sync1.png", "wb") as f:
f.write("".join([
blockS,
suffix2
]))
with open("collision-sync2.png", "wb") as f:
f.write("".join([
blockL,
suffix2
]))
Amazing, our image contains the same pattern (ascii art, sKIP, 0xdeadbeff…). So, the magician must have used this tool.
Recovering the second image
Both images have the following format:
| Image 1 | Image 2 |
|---|---|
| Common_prefix | Common_prefix |
| BlockS (short coll) | BlockL (long coll) |
| Common_suffix | Common_suffix |
So, BlockS and BlockL are obtained using the UniColl attack. However, since we only have the Image1, we don’t know BlockL and then can’t generate the Image2.
At this point, I decide to give a try to HashClash.
We’re going to extract the prefix (with the BlockS) and the suffix of PhazeToGround.png.
dd if=PhazeToGround.png of=prefix.bin bs=1 count=80
dd if=PhazeToGround.png of=prefix_blockS.bin bs=1 count=80
dd if=PhazeToGround.png of=suffix.bin bs=1 skip=192
Here’s the extracted prefix:

Then I computed the collision using hashclash:
scripts/poc_no.sh prefix.bin
When doing a binary comparison between the 2 files, there are always 2 bytes that differs at the same offset.

At this point, I know that the byte at offset 74 is always 0 for the short coll and 1 for the long coll. So, I just have to guess the byte at offset 138 which gives me 256 possibilities.
Here’s my script:
with open('prefix_blockS.bin', 'rb') as fd:
content = list(fd.read())
content[73] = chr(1)
for j in range(256):
content[137] = chr(j)
with open('prefix%i.bin' % j, 'wb') as fd:
fd.write(''.join(content))
Let’s run everything:
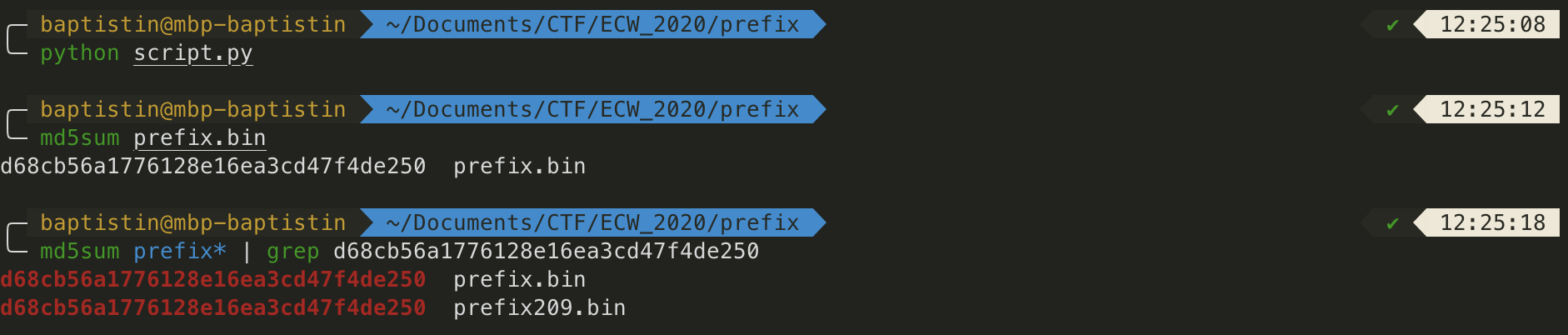
So, now we have prefix.bin=prefix + BlockS and prefix209.bin=prefix + BlockL that have the same MD5.
Now we just have to append the image suffix to prefix209.bin and the new file should have the same MD5 hash as PhazeToGround.png.
Now we append the suffix.bin to prefix209.bin and check the hashes.
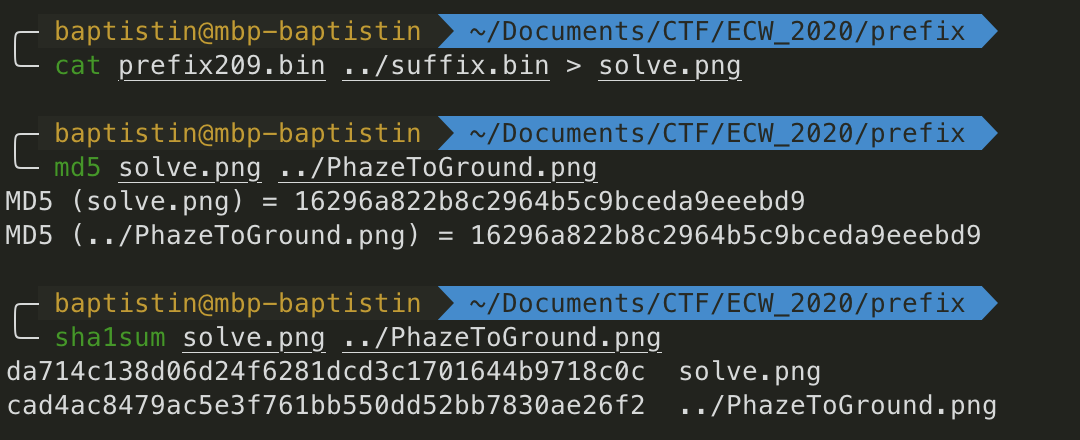
We have the same MD5 but a different SHA1.
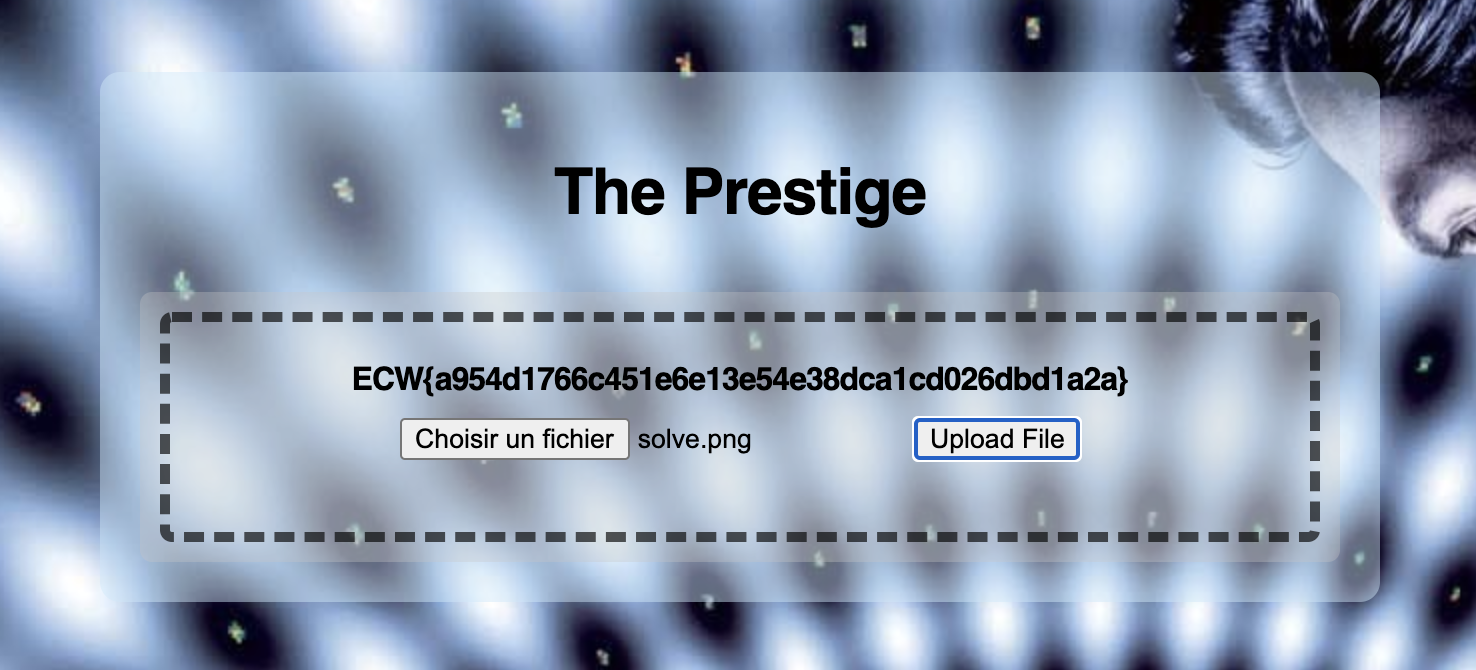
Conclusion
This challenge was a little different from the ones we usually see when talking about collission. It’s a good way to learn a lot of things related to hash algorithms and have a better understanding of the different weaknesses.
--
Kn0wledge